来源:丁香科研
经常有医生朋友来问「我,科研小白一枚,下定决心搞一篇 SCI,但努力都不知道往哪个方向 」
」
经过我多方咨询大佬,帮大家打探到啦,小白最适合这 3 类:
综述、回顾性研究、数据挖掘
当然,大家要根据发文需求选择最适合自己的,但其中有一种类型是怎么都不会出错的,那就是数据挖掘,尤其是霸占 C 位的肿瘤数据挖掘,为什么呢?
7 大优点,各癌种都能挖
▎可挖数据多、且类型丰富;
▎分析角度多样,每年都有新热点;▎省力,无需随访和实验;
▎接收的期刊广,命中率高;
▎原始研究,发的是 article;
▎可晋升,可毕业,可申国自然;
▎周期短,适合时间紧张的人;
有朋友一听到肿瘤,就开始没自信了,这这这,自己能行吗?
行,你当然可以!肿瘤数据挖掘还真不需要有啥基础,你只要知道「DNA 转录成 RNA,RNA 翻译成蛋白质」就足够了。
为什么会说到 DNA、RNA、蛋白质呢,其实,肿瘤数据挖掘围绕的就是这三者,今天重点说一下最好做的 DNA 和 RNA。
——先说 DNA,即基因组学——
大家做的话,聚焦这 3 点:染色体、突变和甲基化。其实,做起来很快,举一个例子:
这两篇文章,就是简单的将人群是否发生某基因突变,分成两组,看免疫治疗的预后差异,最后队列验证确实有差异,然后就发了篇 10+ 的SCI。
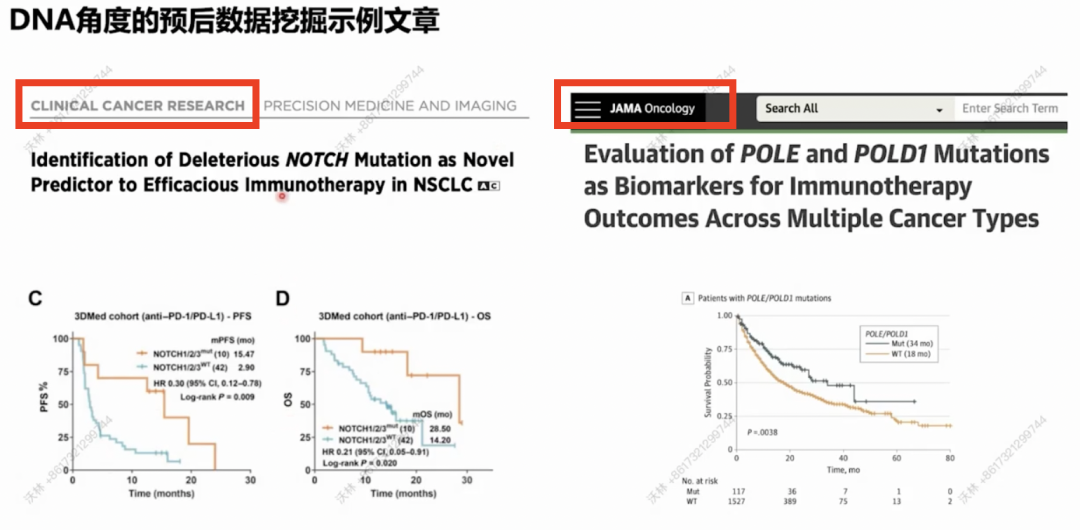
拿你来说,先选定所在科室的一个癌种,然后从公开数据库挖掘到临床患者的数据,锚定一些可能有关的基因,去分类,看差异,再简单验证一下,就齐活了。
——再说 RNA,即转录组学——
如果说 DNA 好做,那么 RNA 先对来说更具优势,因为它不仅好做,还好发,可做的方向也更多,8 大方向随便选👇
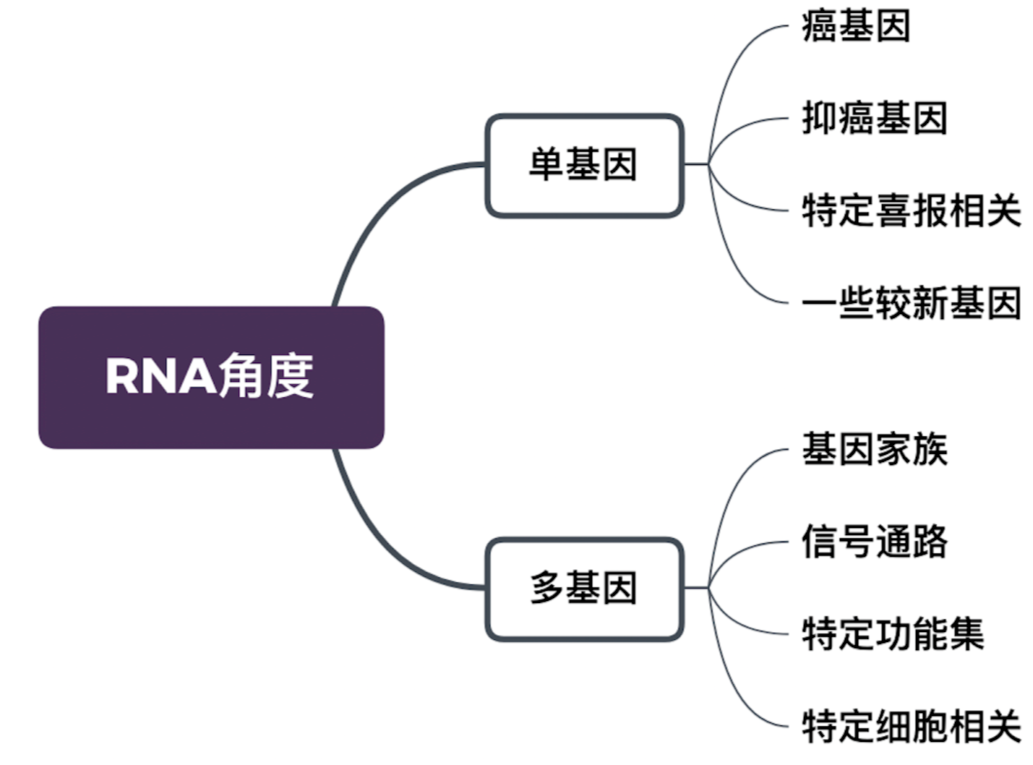
单基因的话,可以做单癌种和多癌种,多癌种更好发,单基因会更简单。多基因通常只做单癌种,多基因的结果较容易被接受。
——王炸:肿瘤数据挖掘 + 预后模型——
我们知道,肿瘤致死率高,所以肿瘤数据挖掘结合预后研究,不仅把肿瘤研究的难度降低了,研究价值也更大了,大家投稿会有更多的临床意义加成。
简单来说,预后模型构建可分为 5 步,其实就是「找预后因子→筛预后因子→预后因子组合→模型判断→价值意义」
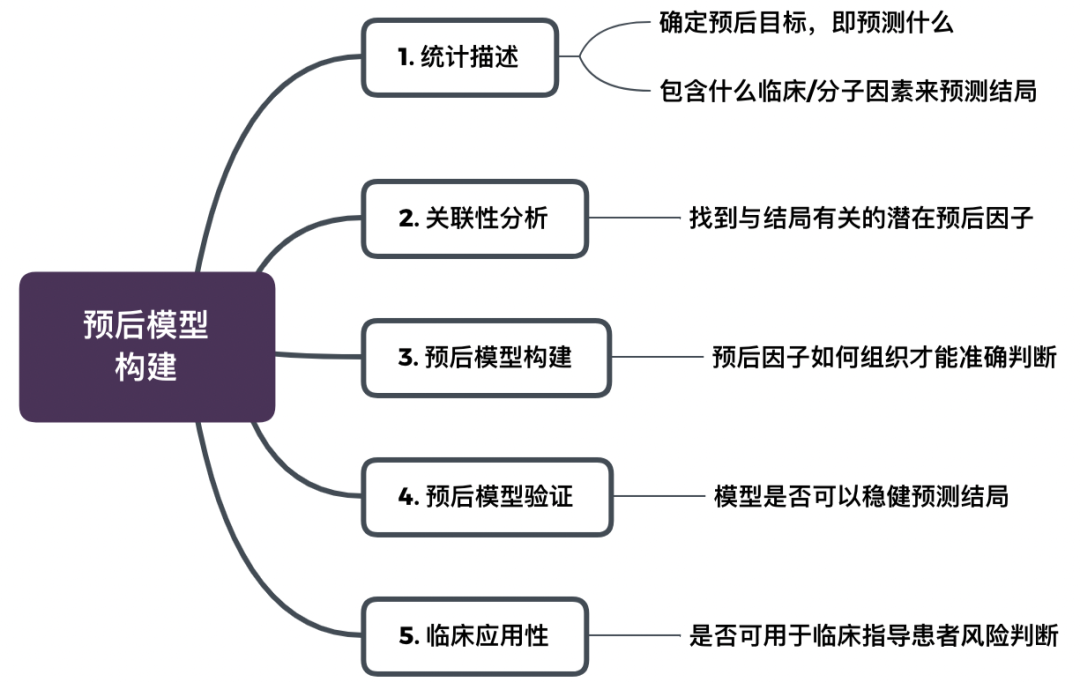
其实啊,公共数据库,其实就是让不同的人,通过不同的角度,反反复复的用,但也可以理解为,挖完了,就没了,你还不开始做吗?